8-9 апреля "Яндекс" провел обновление своего поискового алгоритма, новая версия которого известна под названием "Анадырь". Впервые апдейт был заявлен в марте на конференции NetPromoter Александром Садовским, руководителем отдела веб-поиска компании "Яндекс".
Как только выдача "Яндекса" изменилась, на форуме searchengines.ru началось его бурное обсуждение. В частности, оптимизаторы заметили, что произошло уменьшение значимости ссылок в пользу контента сайта, увеличилось внимание к возрасту сайтов, появилось больше, чем раньше, ресурсов с бесплатных хостингов, а также результатов с Wikipedia.
Об основном же изменении в "Анадыре" Roem.ru рассказал Андрей Кузьменков, рукодитель проектов компании "Ашманов и партнеры": "Главное нововведение - "Яндекс" ввел геотаргетинг в выдаче. "Яндекс" сейчас старается показывать в выдаче пользователям в первую очередь сайты из их городов и регионов. Пока это у него получается не лучшим образом. Выдача местами очень странная. Более того, сегодня произошел заметный "откат" назад". По словам еще одного руководителя компании, занимающейся поисковой оптимизацией, попросившего не раскрывать его имя, "Выдача "Яндекса" сейчас настолько странная, что логично ожидать ее отката на позиции недельной давности и некоторого переосмысления действий поисковика уже после разбора полетов внутри компании".
В отличие от других нашумевших апдейтов (например, "Магадана"), сопровождавшихся активным общением представителей поисковика с оптимизаторами, сейчас наблюдается затишье. Разве что руководитель отдела качества поиска "Яндекса" Денис Расковалов отписался на searchengines.ru о новой выдаче: "Могли что-то и упустить, в частности, поэтому форум и мониторится. Ждем примеров". Тем не менее, и Расковалов, и Александр Садовский не смогли на момент публикации ответить Roem.ru на вопрос о том, что за новый алгоритм запустил "Яндекс".
Андрей Кузьменков объясняет молчание "Яндекса" так: "Похоже, сейчас идет тестирование нового алгоритма ранжирования. Отчасти этим объясняется отсутствие каких-либо сообщений в блоге компании (обычно о таких заметных нововведениях Яндекс своих пользователей информирует)".
Осторожны в своих оценках и другие оптимизаторы: Сергей Кошкин, руководитель компании SmartSEO, также считает, что судить о действиях "Яндекса" рано: "Наблюдается разная выдача по разным регионам (на Украине, в разных городах РФ и т.п. - разные сайты в топе)
По умолчанию регион пользователя определяется по IP. Можно потестировать разницу, указывая разные города на странице настроек
Тема на оптимизаторском форуме разрослась более чем на 2000 комментариев - похоже, это рекорд. Общего мнения нет, хотя многие недовольны выдачей в регионах - пытаясь отдавать региональные сайты "Яндекс" в выдаче показывает в том числе и совсем нерелевантные сайты.
Результаты пока "пляшут", видимо поэтому "Яндекс" и не комментирует событие - не исключен "откат". Мы выводы пока не делаем - подождем до следующей недели".
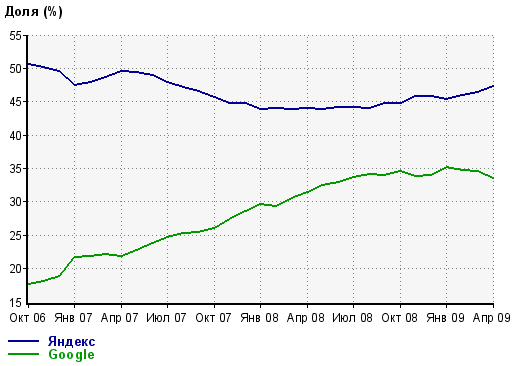
Стоит отметить, что на данный момент, даже старая выдача "Яндекса" показывала очень неплохие результаты - компания существенно подвинула Google по популярности как среди российских пользователей Рунета, так и среди западных:
Добавлено: После публикации материала, "Яндекс" в своем блоге рассказал об изменения в алгоритме. Отмечено, что "Яндекс" лучше научился разбираться с омонимами, однако о региональной заточенности выдачи ничего не говорится.

Добавить 47 комментариев
Лушче был бы заголовок «Яндекс», Анатоль, а надо ль «Анадырь»?
Я честно скажу, что все два дня, пока корр бегал между мной и «Яндексом» мучительно думал, какой должен быть заголовок, но так и не придумал. Отчасти из-за того, что в ситуации когда ньюсмейкер не дает комментариев я чувствую себя не очень уверенно. Когда позиция ньюсмейкера озвучена легче — есть с чем спорить, есть относительно чего высказывать свое мнение. Но… не написать по этому поводу тоже нельзя. Так что читайте что есть на текущий момент.
Локализованная выдача — это очень плохо для региональных интернет-магазинов, торгующих на всю Россию. Наш клиент, например, находится в Петербурге, а большую часть заказов отправляет в Москву. И вот с какой стати лишать его заказчиков, отдавая их в руки невнятных конторок, единственная «заслуга» которых — в местонахождении офиса?
Проверка студийной аппаратуры!
Анадырь, анадырь… я ж вам говорила — Арзамас. http://webmaster.ya.ru/replies.xml?item_no=3255
С надеждой и гордостью встречают это известие веб-мастера из славного города Арзамаса :)
Так интернет магазин, торгующий на всю Россию не должен локализоваться, так как это не локальный сайт Локальный сайт это сайт, который уместен только для локальных пользователей например, местное кафе по запросу «кафе» или местная горадминистрация по запросу горадминистрация Магазин из Екатеринбурга, который торгует на всю Россию вовсе не локальный магазин и должен считаться глобальным
Не могу понять Кто главнее Садовский или Расковалов? Кто кому начальник? А то пишут «Садовский и команда поиска», то «Расковалов, начальник глуппы поиска»
Как всегда хрень очередная. Опять программеры рулят алгоритмами, что сами придумали. Вот пример — есть ньюсмейкер, которого в яндекс=новости не берут, определяя коммерческой фирмой. Далее — 100 сайтов коммуниздят инфу с этого источника и монетизируют траф. Вопрос — почему Я. не считает этот сайт источником?. Может быть 100 находок, кондопог и анадырей, но прозрачности Я. выдачи это не прибавит. Хреновый, но популярный сервис.
Наверное Садовский, он старше? Что до источников и того, что его не берут в News.yandex.ru — он может быть не источником, а хорошим тематическим агрегатором. То есть, все что есть по теме в одном месте. Для мониторинга, чтения и копипиздинга — удобно. А вот «Яндексу», поскольку он эти тексты сагрегировал из оригиналов а на тематическую навигацию не претендует, включать этот сайт не нужно. Совершенно типичная ситуация.
Ситуация могла бы быть типичной, если бы Я. не заигрывал с Сео-неисточниками. Для Я. это тупо траф. Траф републикаторов. Нет?
Траф? А что, источники генерируют «Яндексу» существенный трафик?
Олично, Юрий! Вы что, считаете, что правда в чем? В том, что источник-есть источник, или в том, что кто-то генерирует для Я. траф?
Секундочку. Давайте уточним — это источник эксклюзивных новостей? Или он их откуда-то берет? Если сами ищут, берут комментарии — минус «Яндексу». Вы можете попасть в News.yandex.ru, показав свой эксклюзив Татьяне Исаевой. Если лишь рерайтят или копируют — зачем вы нужны «Яндексу»? Он лучше возьмет эти же новости из первоисточников.
Эксклюзив. Сам удивился, что не взяли в ленту. Думаю, что модераторами нынче плохо рулят))).
По-моему «Яндекс» оказался перед Анадырем без ориентиров Обычно он гнался за Гуглом, внедрял и придумывал новые фишки. Было ощущение догоняющего, как мне кажется. Несмотря на лидерство в Рунете А вначале года Гугл спекся, то ли из-за сокращений, то ли еще из-за чего-то. И тут «Яндекс» порвало. Оказавшись сам перед выбором пути, он не смог найти верный, который однозначно приведет его к победе. Главное сейчас — какие выводы сделают в Яндексе относительно своей выдачи.
По-моему «Яндекс» оказался перед Анадырем без ориентиров. Обычно он гнался за Гуглом Ну это ладно. Традиционный заход на тему «гугль велик, а яндекс жалкая китайская подделка, которому надо заново изобретать колесо, вместо того, чтобы…» Но… А вначале года Гугл спекся, то ли из-за сокращений, то ли еще из-за чего-то. И тут «Яндекс» порвало http://roem.ru/2009/04/07/addednews10302/ как насчёт этого?
А при чем тут это? Яндекс еще не вставляет выдачу по карте для вашей местности как это делает Гугл (по той ссылке, что Вы дали) Выдача карты с бизнесом и выдача просто локализованных результатов это две совершенно разные вещм (второй гугл занимается в штатах уже года три-четыре, не знаю как это у них в России работает)
(второй гугл занимается в штатах уже года три-четыре, не знаю как это у них в России работает) геотаргетингом при поиске в веб занимались еще в 2000 году см Ding Gravano, Shivakumar в VLDB за 2000 год или Garcia Molina в WebDB за 1999 всякий геоIR с подсовыванием пользователю страниц исходя из его положения был очень популярен в 2006-2007, Schockaert SIGIR 2007, mining геозапросов из логов Mei в WWW 2006, Backstrom WWW 2008 Ну и большие поисковики это поддерживают с 2005-2006 примерно При поиске craiglist из чикаго или лос анжелеса или сан франциско вы получаете локальные странички и на гугл и на яху, это относится к другим локализуемым запросам также.
У яндекса было вот что http://koshkin.livejournal.com/359586.html но очень быстро исчезло. Отключилось.
сложный вопрос на самом деле
Вы знаете, если бы этот гео корректно ввели, то можно было бы его обсуждать, а так, недоГЕО, недо Анадырь, который переименовали в Арканзас… Недовыдача региональная и косяков порядочное количество. Хорошее дело не переименовывают, поэтому получилось вместо как луЧЧе, как всегда )) Я не знаю как яндекс справится и справится ли, когда вышеупомянутые онлайн-шопы будут клепаться: Онлайншоп в Казани, онлайншоп во Владике, онлайншоп в Ебурге итд Я также не пойму почему по запросу эвакуатор в Москве в выдаче эвакуаторы Питера. Да много чего не пойму. Может кто объяснит? Зы с удовольствием бы послушал мнение Ашманова.
Мне доводилось слышать, что в Яндексе народ сильно гоняется за квартальными премиями. Поэтому часто к концу квартала выпускают весьма недоделанные и неработающие приложения или апдейты, так как группа старалась получить премию за этот квартал и больше заботилась об окончании в срок, чем о реальном качестве. Скорее всего это относится и к «Анадырь». Народ не заботится о долговременной выгоде для компании (а значит и для себя), а заботится о быстром получении премии за этот квартал.
А почему отключилось? Что было не так?
Кстати, в плане траффикогенерации и карт хорошие и правильно сделанные карты в выдаче уменьшают трафикогенерацию Многие локальные запросы вроде «седьмой континент» или даже «магазин постельного белья» направлены на поиск адреса. Если пользователь получит адрес прямо на странице результатов поисковой системы, ему вовсе не надо кликать на сайт «седьмого континента» и искать адрес ближашего магазина там.
для этого поисковая система должна знать адрес пользователя с точностью до дома, а также откуда-то взять адреса всех магазинов. В этом направлении сейчас развивается мобильный поиск, который местонахождение определять умеет
На знаю, что там за Анадыр, но по http://analyzethis.ru/ у Янлекса осталось все хорошо.
Костя, там же из разных регионов показывают разную выдачу. Как теперь мерять качество поиска?
По России пока только три выдачи: Москва, Питер и все остальное. Будем мерять по Москве ессно :)
Ашмановские темсты очень важный и хороший тест для измерения качества поиска «в целом», но они грубый тест чтоы измерять какие-то детали Вы можете полностью поменять в лудшую или худшую сторогг алгоритм для весьма важных запросов вроде —актуальных запросов (популярных сейчас в силу каких-то событий, «пасха», «как красить яйца», «как провести седер», «акции автомобилистов» «ядерное оружие» «сомалийские пираты» «столкновения в тайланде») —запросы с локальным интересом, уже обсужденные в этом топике и тесты Ашманова совершенно не заметят изменений в выдаче, так как этих запросов в их базе нет и как их мерять они не знают (для одних запросов маркеры надо раставлять в зависимости от геогр местоположения пользователя, для других маркеры зависят от времени запроса)
простите за ошибки, пишу с маленькой клавы, попадаю мимо букв
Кстати, а как там насчет редиректа Тут уже писали, что Яндекс не знает, что такое редирект, Ашманов не знает, что такое редирект, и поэтому многие неправильные результаты у яндекса отмечаются как правильные у Ашманова, потому что «два минуса дают плюс» Ашманов или Яндекс поправили редиректы Смешно, если Яндекс научится работать с редиректами, а Ашманов нет, то яндекс «потеряет» качемство выдачи по Ашманову, хоть система станет лучше Тоже самое относится к размеру индекса. Яндекс не умеет полноценно отделять с дубликатами документов и для запросов все дубликаты выдает в выдачу. Поэтому Ашманов дает Яндексу дополнительно очко по сравнению с другими системами, которые умеют отсеивать дубликаты. То есть «плюс» дается за то за что надо давать минус. Если Яндекс научится отсеивать дубликаты, то Яндекс немедленно упадет по ашмановским текстам на размер индекса, причем очень сильно, так как для некоторых запросов в тестах Ашманова дубликаты — основная часть выдачи (сотни дубликатов для нескольких оригинальных документов).
> гугл занимается в штатах уже года три-четыре, А можно поподробнее? Ссылку на статью Matt Cuts, или на постинг в блоге Гугла, желательно примеры запросов с регионами, желательно в широком спектре тем и интенций. Я как-то ничего найти не смог сходу. Только не надо ссылок на студенческие работы с научно-теоретических конференций.
> с другими системами, которые умеют отсеивать дубликаты А такая уже есть? И сколько в ней вы намеряли полудублей, снятых с выдачи? http://download.yandex.ru/company/paper_76_v1.pdf
А можно поподробнее? Ссылку на статью Matt Cuts, или на постинг в блоге Гугла, желательно примеры запросов с регионами, желательно в широком спектре тем и интенций. В смысле? Вы ожидаете, что я Вам буду исследования делать на 1 000 000 запросов? Вы же специалист по поиску, это Ваша работа. Я только знаю, что уже очень давно набрав craigslist после навигационного сайта, будет стоять региональный сайт крэглист, тоже самое относится к другим запросам от онлайн и оффлайн магазинов до туризма («парк развлечений») или например, правительства («муниципалитет» «налоги») . Это то, что я наблюдаю года 3-4. А уж широкий спектр тем и интенций это Ваша работа, я это оценить не в состоянии
Надо Амшанова попросить, чтобы при измерении индекса он 1 проверял реальное число результатов выдаваемое поиковиков, а не первой строке «найдено столько-то документов» 2 отсеивал дубликаты и полудубликаты, а еще лучше наказывал за них тогда можно что-то говорить А что такое полудубликаты? Вот, например, когда в ЖЖ идет очередной флэшмоб и все копируют один и тот же пост (вот этот, например http://sgray1.livejournal.com/16244.html) и сотни и тысячи «документов» (копий друг друга) через пару дней появляются в выдаче (можете попробовать по любому слову из того поста) Это дубликаты или полудубликаты?
> Надо Амшанова попросить, чтобы при измерении индекса он > 1 проверял реальное число результатов выдаваемое поиковиков, а не первой строке «найдено столько-то > документов» Это речь идет про анализатор полноты индекса? Он не смотрит на строку «найдено N документов на M сайтах», он «листает» результаты поиска до конца и считает реально предъявленное число документов. Именно для этого там используются сверхредкие запросы, такие что поисковик по ним находит первые десятки или сотни документов, так чтобы их можно было пересчитать все. > 2 отсеивал дубликаты и полудубликаты, а еще лучше наказывал за них Это спорное утверждение. Существует масса случаев, когда текстовые дубли (или почти дубли) присутствуют на многих сайтах сознательно и это не свидетельство воровства текстов. Например, описания одного и того же товара в разных магазинах. Вот например Все эти сайты совершенно сознательно имеют документы с идентичным текстом, которые есть перевод оригинального описания данного товара от вендора. Есть и другие случаи. Так что поисковики с дублями что-то делают, каждый свое, но единого эталонного поведения нет и анализа этого поведения методом сравнения с эталоном я не могу придумать.
Кто говорил про регионализацию результатов у гугла. Можете ссылочку привести самому интересно посмотреть. Пока у меня получается что гугль таргетит рекламу, но не таргетит результаты поиска. Сравни: http://www.google.ru/search?hl=ru&q=pizza&btnG=++Google&lr=&aq=f&oq=&gl=us&gr=us-ca http://www.google.ru/search?hl=ru&q=pizza&btnG=++Google&lr=&aq=f&oq=&gl=us&gr=us-ny gl это у гугля страна gr это у гугля регион. По двум приведенным ссылкам у меня получается полностью идиентичная выдача за исключением рекламы. Народ в нашем американском офисе тоже таргетинг найти не смогли. Может что-то не так набираю?
p.s. sorry, для чистоты эксперимента забыл поменять ru->com и hl=en Вот правильные ссылки: http://www.google.com/search?hl=en&q=pizza&btnG=++Google&lr=&aq=f&oq=&gl=us&gr=us-ny http://www.google.com/search?hl=en&q=pizza&btnG=++Google&lr=&aq=f&oq=&gl=us&gr=us-ca Но результат тот же самый
ничего не знаю про gr Когда я езжу из ЛА в НЙ, я никаких gr не ставлю, подозреваю, что гугл проставляет регион по ip, а не gr Судя по выдаче этот gr гуглом игнорируется так как карта у гугла в выдаче точно локализованная (разная даже когда я в офисе и дома) а в ваших примерах она одинаковая и локализована для моего ip, а не gr=us-ny, gr=us-ca
Анатолий попробуйте разные американские прокси
из недавнего когда я искал lottery winning numbers lotto winning numbers я получал вверху выдачи сайты с зависимости от штата где нахожусь (сайты лотереи данного штата)
lottery winning numbers и правда отличается: С российского ip http://www.picamatic.com/show/2009/04/17/11/13/3302231_1265x1552.png С американского http://www.picamatic.com/show/2009/04/17/11/12/3302210_1265x1487.png
Упс, да, пропустил слово «региональная», — ну пятница, вечер :) Вот: Monroe, LA -> http://www.picamatic.com/show/2009/04/17/11/32/3302541_1265x1417.png Portland, OR ->http://www.picamatic.com/show/2009/04/17/11/34/3302571_1265x1457.png
Во Флориде мне стабильно дает лотерею штата флорида
интересно, как эти эксперименты яндекса повлияют на порталы, использующие его поиск?
Судя по тому, что в консоле веб-мастера от Яндекса в отчете по поисковым запросам до сих пор показывается одна позиция в выдаче (ес-сно не соответсвующая реальности, по крайней мере для региональной выдачи), то скорее всего в Яндексе об этом еще никто не думал…