Из официального заявления о причинах сбоя в работе проекта:
В результате технического сбоя во время выкладки конфигурационного файла на все сервера ОК произошли необратимые изменения. В течение 10 минут произошел рост использования ресурсов серверов до 100%. От нас потребовался принудительный рестарт и ручное переконфигурирование значительной части из более чем 5 000 серверов. Это повлекло за собой восстановление работы систем хранения данных и запуск сервисов с нуля.
4 апреля 2013 года произошла самая серьезная авария за всю историю Одноклассников — портал не работал более суток, а потом еще в течение двух дней был доступен в ограниченном режиме. У десятков миллионов пользователей пропала возможность писать сообщения своим друзьям и близким, слушать музыку, смотреть видео и играть в любимые игры на портале. Экспертами и людьми, не обладающими техническими знаниями, выдвигались всевозможные предположения: от взлома хакерами и потери всех данных, до “они поднимают свой MS SQL”. Отношение к произошедшему тоже было разное: от пожеланий скорейшего решения проблем и добрых писем в отдел поддержки пользователей до злорадных комментариев и обвинения сотрудников ОК в некомпетентности.
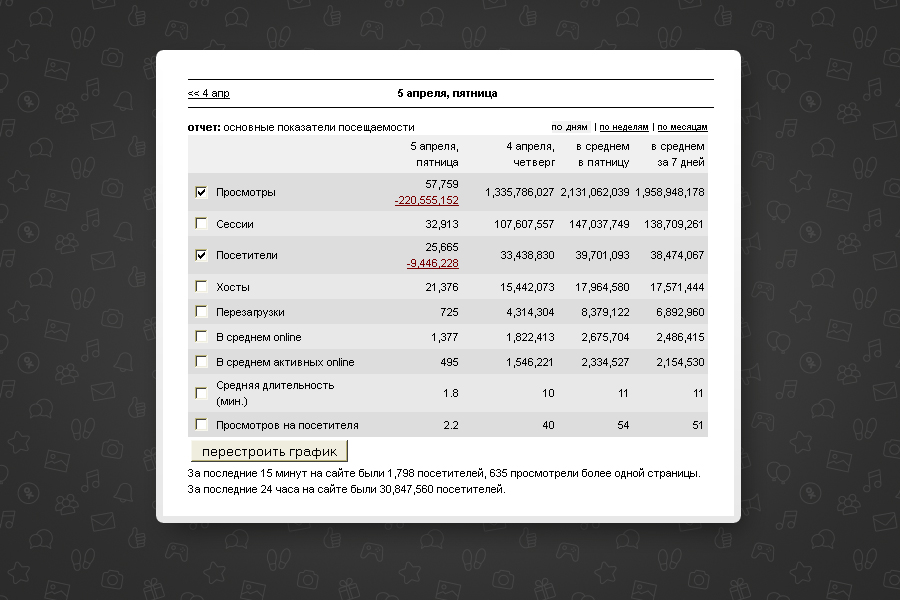
На самом деле ситуация выглядит несколько иначе. Важно понимать, что современные интернет-проекты с миллионами пользователей в онлайне — это очень сложные системы. Если мы говорим про социальные сети, то эти системы могут насчитывать десятки и сотни тысяч серверов, а также компонентов: фотографии, видео, сообщения, графы друзей, рекомендации, лента. Все это состоит из множества баз данных, систем кеширования, серверов раздачи, систем мониторинга и статистики и многого другого.
К примеру, Одноклассники на сегодня — это более 7000 серверов, которые в совокупности обслуживают около 150 различных подсистем.
В любом крупном проекте, разработчики принимают ряд мер для того, чтобы обезопасить себя от аварий, сбоев, отказов и пр. Типичный пример такой проблемы — выход из строя какого-то оборудования (от жесткого диска до аварии на интернет-магистрали, к которой подключен датацентр). Другой пример — ошибка в программном обеспечении. Это может быть неправильно работающий драйвер операционной системы сервера или даже простая ошибка программиста из конкретного подпроекта. Наши решения умеют моментально переключаться с одного оборудования на другое в случае, если автоматика распознает, что с текущим оборудованием что-то не так.
Как все было. Что-то пошло не так или “давай с твоей консоли поправим, будет быстрее, у меня уже закрыто”
К сожалению, мы не можем быть застрахованы от человеческого и технического фактора. В нашем случае, в 2013 году это был человеческий фактор. Системный администратор должен был совершить простое, обычное изменение конфигурации, направленное на починку уже случившейся поломки и на обеспечение безопасности системы. Минутное дело — очевидные изменения. Ничего бы и не произошло, если бы не различия в рабочем окружении сотрудников, из-за которого в конфигурацию пробрался один лишний символ.
Баг в системе централизованого управления из-за лишнего символа испортил конфигурацию еще больше и привел к мгновенному ее распространению на все тысячи серверов. И все бы даже ничего, если бы не баг в системном компоненте Linux, который вместо того, чтобы отказаться читать такую конфигурацию, в течение 10 минут вызвал 100% нагрузку на все сервера. Скорость обслуживания запросов пользователей упала на порядки и из-за слишком большой нагрузки все сервера стали полностью недоступны для управления администраторами.

Как чинили и какие были сложности
Первые 20 минут еще была надежда, что удастся починить так, как и сломали, но быстро пришло понимание, что этого сделать не получится. Для людей, не сталкивавшихся с авариями подобного масштаба, сложно осознать всю глубину проблемы. Представьте себе: творение ваших многодневных трудов на глазах стирается в пыль. Чинить нужно было срочно, но непонятно как, с чего начать и что лучше сделать в первую очередь. То, что было очевидно: для полной починки потребуются дни. Дни сначала ручных, а потом полуавтоматических и автоматических действий со всеми серверами для их «оживления», а потом запуск и восстановление работоспособности всех систем и полной функциональности.

Началась ликвидация аварии: информирование, мобилизация, ручная работа и параллельная автоматизация починки, распределение задач и ролей, дополнительная мобилизация, решение ожидаемых и неожиданных проблем, постоянный контроль, расстановка приоритетов и корректировка действий вплоть до полного восстановления, документирование действий и возникающих проблем для последующего анализа.
Что мешало
В первую очередь, отсутствие плана действий и опыта решения настолько серьезной проблемы. Неожиданные циклические зависимости между сервисами и правка кода “на лету”, хаос в статистике и мониторинге, не готовых к такой аварии, неадекватное поведение служебных систем и сети, вызванное массовыми перезапусками оборудования, поломки уже починенного, запуск сервисов в определенной последовательности с урезанным функционалом из-за недоступности части серверов и сервисов, наличие большого количества систем хранения данных, требующих сложных и продолжительных ручных манипуляций для запуска и, наконец, физические возможности человеческого организма.
Что вдохновляло
Рабочая и продуктивная атмосфера, полная самоотдача сотрудников, поддержка коллег и руководства несмотря на очень большое давление. Многие коллеги не спали сутками, а ребята из других отделов поддерживали как могли: кто едой, кто просто бодростью духа.
Какие выводы мы сделали и что решили изменить
Мы проанализировали информацию, полученную по результатам аварии и ее решения, и полностью избавились от ненадежных систем хранения данных. Помимо этого, внедрили централизованную систему автономного управления серверами, улучшили системы мониторинга и сделали физически невозможным изменение конфигурации на всех серверах за короткий период.
А также:
- Поменяли процедуры изменений на production (сервера, находящиеся в промышленной эксплуатации, то есть непосредственно обрабатывающие запросы пользователей) и ввели review (обязательную проверку еще одним сотрудником) этих изменений
- Поменяли процедуры тестирования служебных систем
- Повысили надежность служебных систем и сети
- Подготовили и постоянно тестируем план действий при аварии
- Несмотря на произошедшее, команда была полностью сохранена. Мы никого не уволили, потому что понимали, что человеческий фактор всегда возможен
На деле любой (даже зарезервированный) компонент может отказать как в нашей инфраструктуре, так и неподконтрольный нам: электричество, системы охлаждения в датацентрах, линии связи и т.д. При этом, мы уже сейчас готовы пережить полное уничтожение любого из наших датацентров без потери данных и приближаемся к готовности обеспечить полностью работающий проект в такой ситуации. Заранее предусмотреть все сценарии аварии невозможно, но можно снизить ее вероятность и грамотно подготовиться на случай, если на ЦОД вдруг упадет крыша соседнего здания из-за урагана или вдруг в город ворвется Годзилла, что, конечно, менее вероятно.

Разница в операционных системах и текстовых редакторах, используемых сотрудниками. Один оставлял дополнительный символ перевода строки, другой нет.