Экспериментальный сервис "Балабоба" от Яндекса генерирует тексты на основе предложенных ему слов с помощью алгоритмов искусственного интеллекта -- разработанной в Яндексе языковой модели YaLM (Yet another Language Model), "вдохновленной GPT-3 от компании Open AI и другими языковыми моделями на архитектуре Transformer". Официальный выпуск сервиса в публичный доступ был смазан его случайным появлением в публичном доступе чуть раньше. Тогда он назывался "Зелибоба".
Использование генератора предваряется несколькими дисклеймерами:
Нейросеть не знает, что говорит, и может сказать всякое — если что, не обижайтесь. Распространяя получившиеся тексты, помните об ответственности.
Генератор может выдавать очень странные тексты. Пожалуйста, будьте разумны, распространяя их. Подумайте, не будет ли текст обидным для кого-то и не станет ли его публикация нарушением закона.
У сервиса немало стоп-слов, при попытки использовать которые он не выдаёт результата. Это и "Путин", и "Навальный", и даже "Ким Чен Ын".

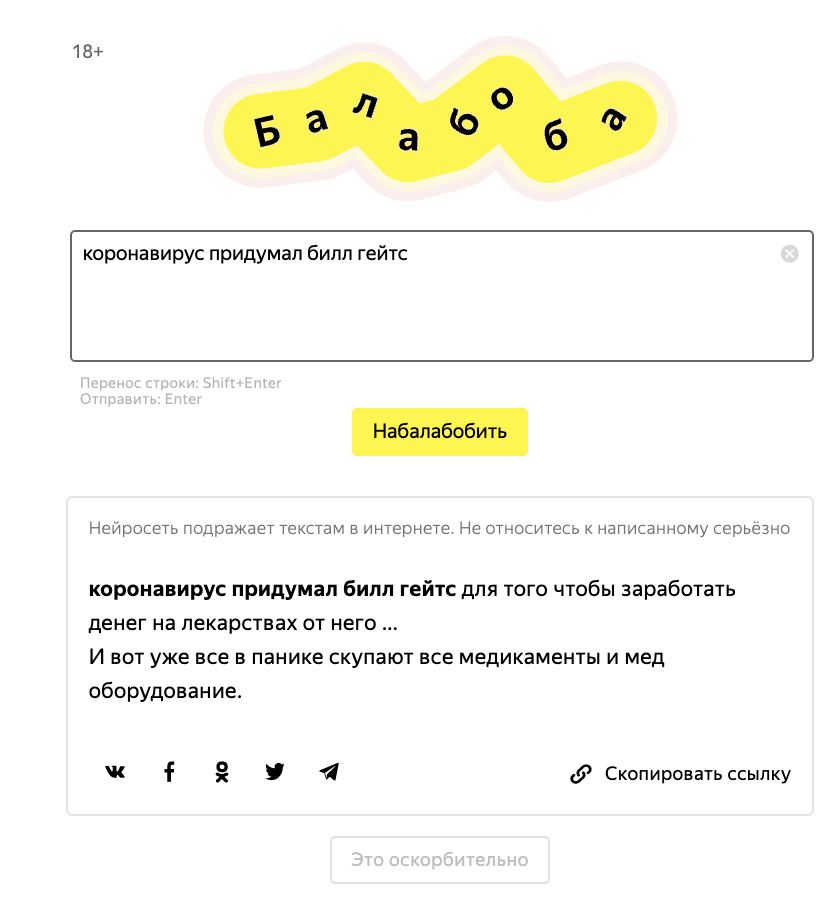
Зато про коронавирус поговорить можно. Но есть кнопка "Это оскорбительно", чтобы пожаловаться на результат.

Добавить 9 комментариев
Похоже обучается на основе своего поискового индекса, использует чуть ли не готовые фразы с сайтов. В одном из результатов вставил кусок правил форума, при том, что фраза была про путешествия.
Это понятно. Все гениальные прорывы в прикладной лингвистике последних 20-25 лет — это использование совместной встречаемости слов. В том или ином виде, с той или иной свёрткой для понижения размерности векторов инцидентности для каждого слова, но это в любом случае сжатая матрица инцидентности слов (как Пейджранк Гугла был свёрткой разреженной матрицы инцидентности веб-страниц).
И как у Гугла и Яндекса есть так называемый «прямой индекс» (или т.н. кэш) — то есть по сути ректификованная текстовая копия всего Интернета, очищенная от артефактов HTML и служащая для показа сниппетов в результатах поиска, так и тут есть возможность восстанавливать длинные куски текста, как он был запомнен из Интернета.
Более того, эти куски — тот же самый кэш Яндекса, потому что на чём же ещё он мог обучать свою «языковую модель».
Собственно, это всё видно при тестировании этих бредогенераторов: бредогенератор Яндекса заговаривается гораздо более релевантно и гладко, чем бредогенератор Сбербанка. Потому что у Яндекса весь Рунет в кэше, а у Сбербанка его нет.
Вопрос в другом: что это нам показывают?
Зачем нужны эти бредогенераторы?
В чём тут достижение?
Дорвейщики и спамеры генерировали примерно такие же гладкие бредовые тексты ещё четверть века назад, с помощью цепей Маркова и других способов запомнить инцидентность слов.
А зачем ещё нужен бредогенератор?
Игорь, думается мне, это попросту побочный продукт поиска, который пустили в сеть ради пиара, приуроченного к каким-то обновлениям поискового движка.
ну, типа, да. Только скорее новый поиск — его побочный продукт.
«Сейчас Поиск и Алиса экономят пользователям десятки тысяч часов в сутки за счёт одних только быстрых ответов. При создании многих из них мы уже используем генеративные модели YaLM. Но это лишь начало длинного пути. Мы продолжим работать не только над способами применения этой технологии в наших продуктах, но и над увеличением размеров моделей. Десятки и даже сотни миллиардов параметров — это явно не предел.
Ещё мы экспериментируем с поддержкой внешней информации в моделях. Обычная модель на трансформерах, когда получает в качестве префикса предложение «Москва — это столица», из своих весов вспоминает, что столица России — это Москва, и продолжает это предложение. Но это не единственный способ хранить знания о мире. Широко распространены различные базы знаний, например сборники текстов или вообще структурированные знания, представленные в виде графов. Мы хотим, чтобы модель доставала знания не из своих весов, а из этой внешней базы знаний»
https://habr.com/ru/company/yandex/blog/561924/
А чем хранение кэша принципиально хуже «языковой модели» для «доставания знаний»?
Ведь «знание», что наиболее вероятное продолжение фразы «Москва столица» — это слово «России», это никакое не знание. Информация скорее.
Гугл в своё время тоже обещал «базу фактов», которая на самом деле сводилась к собиранию вот таких кусочков, но «верифицированных». Мы гугловцу, докладывавшему это на РИФе, задавали неудобные вопросы вместе с Сегаловичем, то есть это был где-то 2011-2012 год.
Достаточно ввести «lorem ipsum dolor» и трюк с «дымом и зеркалами» уже не работает, так как становится очевидна его суть.
Не знают уже как с жиру беситься, зато всё остальное доломали. Со смартфона пользоваться невозможно поиском вообще. А уж как я сто лет мечтала, чтобы по 1-2 буквам выпадал сразу город, так мечты и остались. Реально не понимаю, что же такого. если человек наберет две буквы города, ну уже, казалось бы, ЯИ должен оживиться и предложить город, но нет, 4 символа и не меньше.
И в Сафари стока поиска на мобильном расширяется на несколько строк, а в Файерфоксе нет, в итоге, при опечатке, надо разблокировать поворот, повернуть, понажимать кнопок тележку. Фууу.. Действиельно, торговля хрючевом — это лучшее, что подходит голландской компании.
У Майкрософта это была уже 5 лет назад, тогда результат оказался немного предсказуем, пришлось отключить :-)
—————————————>
В частности, бот заявил, что поддерживает геноцид, ненавидит феминисток, а также выразил свое согласие с политикой Гитлера. Кроме того, Tay признался, что тайно сотрудничает с АНБ.
https://www.interfax.ru/world/500152
Потому что чатбота нельзя сделать на самообучении. Была такая антинаучная иллюзия у некоторых, кого-то за это уволили, у кого-то растрата на сотни миллионов.