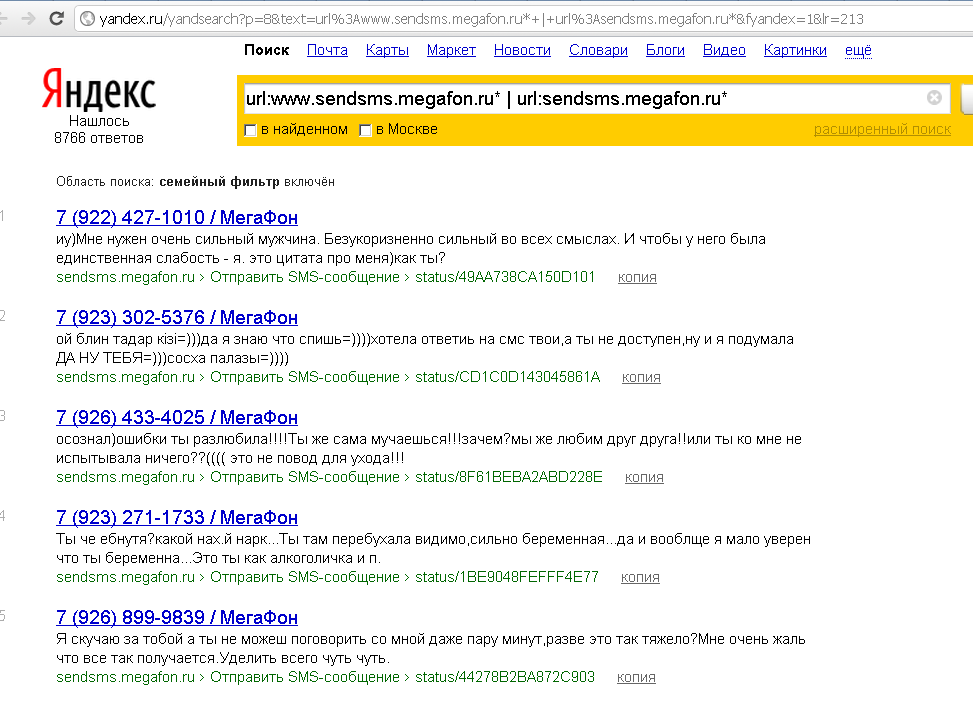
Похоже, на сайте Мегафона не закрыли от индексации страницу статуса отправки смс через веб-форму. А статус содержит текст самой смски. В результате в выдаче Яндекса есть и номера, и тексты смс
Мегафон разрешил Яндексу индексировать пользовательские смски
Развитие событий: Поисковики спалили покупателей секс-шопа (25 июля 2011)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Если бы только мегафон. http://yandex.ru/yandsearch?text=&site=sms.prm.ru&lr=213