Несколько лет работы с проектами в области машинного обучения, участие в соревнованиях Kaggle, работы как с платформенными платными и бесплатными решениями, так и решение задач с помощью языков R&Python дают мне возможность сделать небольшой обзор того, как обычно начинается проект по Machine Learning, какие сложности возникают и как их преодолеть.
Часть 1. Взгляд изнутри
«Как можно верно оценить такую задачу?, - подумал я. - Еще и критерий точности >90%?. Интересно, как они его считают и эта фраза “по каждому сорту”, сколько их там? Ладно, можно готовить очередной опросник».
Я немного утрирую ситуацию, которая происходит достаточно часто, но давайте пройдемся по пунктам:
- Заказчик обычно не знает возможностей машинного обучения и специфики его успешного применения. Например, предсказать спрос по каждому сорту (допустим, этих сортов около 1000) будет в разы сложнее, чем предсказать общий спрос на всю продукцию. А для некоторых сортов и попросту невозможно. Добиться 90% точности для каждого – невозможно почти на 100%. Хотя бы потому, что 10 сортов будут продавать по 1-3 штуке в абсолютно случайном месяце без каких-либо зависимостей, а еще 10 зависят только от желания зарубежных оптовых заказчиков и абсолютно не коррелируют ни с одним показателем из возможных.
Из этого можно вытекает один вывод: некоторые задачи, полностью или почти полностью нереализуемые еще на стадии формулировки. Я подчеркну, речь не о сроках, данных, а именно о формулировке задачи, и наиболее популярные камни преткновения тут – это точность и горизонт предсказания. Невозможно на два года вперед сказать, сколько будет продано молока с ошибкой в 3% максимум, как невозможно для абсолютно всей продукции вашего магазина сделать точный прогноз. Казалось бы, это логично, но на практике “космических” запросов на реализацию хватает.
- Почти всегда встречаются понятия: точность, спрос, отток и другие популярные формулировки. Но мало кто задумывается, как сильно можно и даже нужно углубляться в формализацию этих понятий. Например, разберем понятия точность и отток.
Точность можно измерять разными способами, в интернете легко найти минимум 10 разных метрик. Возьмем одну их простых: модуль разности (прогноз – факт) и поделим результат на факт. Допустим, по факту было продано 100 машин, предсказали 110 машин. Считаем, 110-100 = 10, затем этот результат делим на факт - 10/100 = 0.1. Ошибка составила 0.1 * 100% = 10%. Значит, точность будет равна 1 – ошибка = 90%, что, согласитесь, звучит неплохо.
А теперь представьте, что наша задача предсказать продажи дорогих и редких машин, их продают по 4-10 штук в месяц, подойдет ли нам такая метрика? Допустим, по факту было продано 7 машин, предсказали 9 машин. Считаем, 9-7 = 2, затем делим этот результат на факт - 2/7 = 0.28. Ошибка составила 0.28 * 100% = 28%. Значит, точность 1 – ошибка = 72%. Очень далеко до 90% верно? А ошиблись-то всего на 2 машины…
Очень важно до старта проекта убедиться и обговорить метрику точности решаемой задачи, особенно если от нее зависит его успешная реализация.
Или, например, возьмем понятие отток. Надо понимать, что, если отток воспринимать как «покупатель наших машин в следующем месяце ничего у нас не купит», то это один тип и сложность задачи. А если отток – это «покупатель наших машин еще три месяца покупает наши машины, затем месяц покупает только запчасти для них, затем ничего не покупает», сложность точного прогнозирования этой задачи становится в разы сложнее.
Тут у нас появляется следующий вывод, который несомненно поможет как заказчикам, так и исполнителям: максимально формализуйте и уточняйте требования до старта проекта. Не только требования, но и сами термины. Это, безусловно, важно во всех типах проектах, но в машинном обучении требуется максимально четкой детализации. Несколько примеров, как нечеткая формулировка заставляла пересматривать сроки проекта, а порой и способы его реализации:
- В популярной задаче создания рекомендательных систем был использован алгоритм коллаборативной фильтрации, давайте называть его просто алгоритм. В нем необходимо были данные по оценке пользователем неких объектов. Например, объект Б, оценен на 3 балла из 5. После первичного анализа, появилось слишком много девиантов – людей, чье мнение постоянно не совпадало с мненией большинства. Но как оказалось в дальнейшем, это была оценка пользователей, которые не смотрели фильм или сделали вывод по трейлеру. Пришлось их убирать, а это существенное уменьшение обучающей выборки и некоторые другие сложности. Вот так определили новое понятие – оценка.
- В задаче предсказания некого объекта было определено, что объект един и неделим. И заказчик будет оценивать именно предсказание этого объекта. Оказалось, что объект на определенном горизонте распадается. Т.е. на три месяца вперед, предсказав 100 объектов, мы будем очень точны. Но проблема в том, что на 4, эти 100 уже будут 200-ми, и мы сильно потеряем в качестве. Пришлось усложнять проект, вводив дополнительную модель предсказания деления объекта на два новых объекта. Сроки существенно увеличились.
- Заканчивая эту часть хочется упомянуть об обучающей выборке. В тех случаях, когда мы используем алгоритмы, которые требуют обучения на исторических данных, важно, чтобы история была, верно? И здесь есть несколько важных моментов:
- Нам еще непонятно, какие данные придется выгружать и какие признаки для решения задачи формулировать.
- Достаточно часто разговор скатывается на уровень «дайте нам, все что есть», «нет, вы скажите, что вам нужно, мы выгрузим».
Например, чтобы спрогнозировать отток постоянных покупателей, нам понадобятся характеристики сортов ромашек, данные по продажам, цены, средние значения и так далее. И здесь начинается самое интересное. Потому что, например, использование API Google.Maps или Яндекс.Карты может показать, где расположена ближайшая цветочная точка конкурентов и подскажет, где много ли сколько вокруг жилых домов, и есть ли рядом кладбище. Можем ли мы это использовать? Ведь если рядом через месяц построят оптовую цветочную базу, спрос упадет, а мы этот фактор не внесли в обучение.
А вдруг у заказчика уже есть готовое мобильное приложение, которое позволяет ставить лайки понравившимся сортам ромашек по торговым точкам? И если количество лайков падает, можем ли мы это использовать? В каком виде это хранится?
И логичная ситуация, что по нескольким сортам история продаж - три недели. А прогноз нужен еще на три. Это тоже совсем нерадостная ситуация
Тут нет готового рецепта, на этой стадии нужно очень активно сотрудничать с бизнес-заказчиком задачи. А лучше непосредственно с тем, кто занимается вплотную этой задачей. От этих людей можно узнать множество дополнительной информации. Продавец может вам сказать, что сорт ромашек номер 22 можно предсказывать по-другому, он всегда идёт по 1 штуке на букет других ромашек.
Делаем вполне очевидный четвертый вывод: продумывайте заранее, какие данные могут потребоваться, в каких объемах, и оценивайте качество и полноту обучающей выборки. Чем больше данных, тем лучше, но некоторые могут быть очень трудозатратными ещё на стадии их получения. И как можно чаще и больше общайтесь и узнавайте, какие факторы или особенности есть у всех процессов. Добавить что-то в конце часто бывает проблематичным.
Часть 2. Процесс
- Добрый день, через две недели сможете показать первые результаты? Как ждать три месяца...?
В этой части хочется разобрать сам процесс реализации ML-проектов – если очень кратко, то выглядит он примерно так:
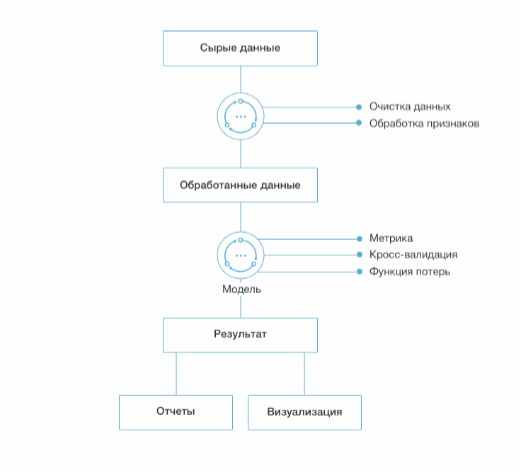
Перед самим процессом нужно понять две очень важные вещи, про которых частенько забывают или просто не знают. Сначала поймем, что умеет в общем машинное обучение.
Машинное обучение умеет:
- Получив объекты (человек, изображение, сим-карта, цветок, пара людей), извлечь признаковое описание объектов (рост, цвет волос, размер одежды, количество детей, образование, наличие смартфона);
- Посмотрев на объекты, научиться:
- Классифицировать (мужчина/женщина)
- Прогнозировать значения для объектов (возраст, доход, рост)
- Группировать (школьники, бизнесмены, политики, любители чая).
Вспомнив всё то, что мы узнали из первой части, приходим к очень необычному выводу: машинное обучение может решать почти все задачи, которые мы можем придумать в рамках тех требований и ограничений, о которых я писал выше.
- Предсказать, сколько погибнет ромашек, а сколько вырастет? Можно.
- Предсказать, какой новый цвет ромашек будет в тренде в следующем сезоне? Легко.
- Классифицировать для нас работников, которые уволятся через год? Запросто.
И т.д.
Что нам понадобиться для этого?
Для первого пункта: данные о температурах, грунте на грядках, чем обрабатывали цветы, их сорта, кол-во осадков, состав воды поливы и т.д.
Для ответа на второй вопрос подключаемся к лидерам мнений (в чем была Бузова последний раз в Instagram?). Распознаем цвет и фасон платьев ковровой дорожки Каннского кинофестиваля, собираем цветовую гамму модных домов Парижа.
Для прогноза об увольнениях собираем данные по опозданиям, рабочим места, количеству сотрудников, близости к метро, логов веб-браузеров и т.д.
И первая важная вещь, которую мы понимаем: при наличии обучающей выборки и исторических данных для реалистичного горизонта в будущем, мы можем предсказать почти все. Вопрос здесь только в точности и целесообразности.
Но надо четко понимать, что чем сложнее и нетривиальнее задача, тем трудозатратнее и с бо́льшей долей неизвестности качества она будет решена. Примерный список задач, которые можно решать на текущий момент, которые не находятся на стадии «исследования» и существуют достаточное количество успешных практик и вариантов решения:
- Обработка естественного языка (Natural Language Processing) – машинный перевод, анализ отзывов, выделение названий, логические выводы.
- Анализ социальных сетей (Social Network Analysis) – рекомендация друзей, поиск сообществ, выделение лидеров мнения.
- Анализ изображений и видео (Computer Vision) – выделение лиц на изображениях, извлечение номеров, названий с камер, стиля, трендов в одежде.
- Анализ аудио сигналов (Signal Processing) – распознавание речи, классификация музыки, рекомендация плейлиста.
- Рекомендательные системы (Recommended Systems) – рекомендация товаров, друзей, прогнозирование оценок к фильмам.
- Поиск ассоциативных правил (Association Rule Learning) – построение логических правил, анализ чеков.
- Поиск спама (Spam Detection) – Gmail, Mail.ru, Яндекс.Почта, …
- Сегментация потребителей (Customer Segmentations) – Facebook, Google, Яндекс, Вымпелком…
- Выявление фрода (Fraud Detection) – Google, Facebook, Вымпелком, Сбербанк…
- Прогнозирование оттока (Churn Prediction) – Amazon, Netflix, Вымпелком, МТС, Мегафон, МГТС…
- Распознавание речи (Speech Understanding) – Apple (Siri)…
- Классификация изображений (Image Understanding) – Facebook, Google, Instagram, Яндекс, Mail.ru…
Такие задачи уже имеют свой алгоритм решения, и их можно почти без рисков реализовывать и внедрять.
Вторая важная вещь, которую нужно понимать перед началом реализации проекта, это требования к ресурсам и результаты пилота. Специфика реализации всего вышеперечисленного такова, что трудозатраты пилота и не-пилота часто бывают идентичны, а мощности для реализации часто на время пилота требуются такие же или даже выше, того, что будет в продуктивном решении.
Разберем эти моменты поподробнее на нашем случае предсказания оттока покупателей каждого сорта ромашки. Давайте подумаем, как тут можно ограничить пилотный проект? Например, так:
| Пилот | Полный проект |
| Предсказываем 1-2 сорта | Предсказываем все сорта |
| Предсказываем все сорта, но для одной точки | Предсказываем для всех точек |
| Предсказываем три разные по типу точки и трем максимально разным сортам | Предсказываем сорта и точки |
А теперь по трудозатратам:
| Что делаем для пилота | Что делаем для полного проекта |
| Собираем все признаки | Собираем все признаки |
| Делаем преобразование и подготовку данных | Делаем преобразование и подготовку данных |
| Перебираем различные алгоритмы, ищем лучший результат | Уже знаем лучшие алгоритмы, настраиваем их и получаем результат |
В этой схеме время на продуктивное решение может получится даже меньше, чем время в пилотном проекте. Конечно, бывают и иные ситуации, но и эта совсем не редка. Более того, некоторые проекты, в которых я участвовал, в принципе не могли пилотироваться, потому что для требуемой точности нужны были все возможные данные и ресурсы.
После того, как мы поняли эти две важные вещи, перейдем к популярному списку проблем, которые могут возникнуть при реализации:
- Новые форматы данных или их виды. Если для обучения мы использовали температуры в градусах, а теперь берем данные по ромашкам на грядках, то, как только для предсказания поступят данные в других измерениях, результат будет плачевный.
- Данные, которые мы используем для обучения, совсем не похожи на данные, на которых мы будем проверять успешность проекта.
- Требования показать промежуточный результат или пилотный результат за очень короткий срок.
- Нетривиальные задачи, которые можно реализовать, но для них невозможно предоставить референс, уникальные задачи.
- Многочисленные ошибки в исходных данных. Один департамент считает готовую продажу, это когда есть запись в базе, а другой, только когда данные придут на расчетный счет.
- Невозможность соединить данные. В одной среде это ID покупателя, а в другой ID операции. Связи между ними нет. Ее можно сделать, но понадобиться время.
- Использование будущих данных. Например, полные продажи, которые учитывают еще и законтрактованные оптовые продажи за два месяца.
Это далеко не весь список, есть еще много технических моментов, но они скорее относятся к технической части, нежели чем к идейной, которую я раскрываю в статье.
В заключении хочется сказать, что понимание вышеописанных особенностей задач сферы машинного обучения существенно упростят реализацию проектов, а иногда помогут вообще избежать заранее рисковых проектов. Они помогут правильно подходить к общей оценке проектов и понимать достаточный и необходимый набор данных и условий.

Добавить 11 комментариев
В статье совершенно выпущена одна из главных проблем: оценка качества решения. И вообще детекция наличия решения.
Об этом сказано в начале, но потом опущены и такая стадия, и описание проблем с заказчиком.
Большинство заказчиков не понимает, что такое решённая задача, как тестировать решение ИИ, что вообще является решением, каковы критерии качества, не знает, что такое ложные срабатывания и пропуски цели, полнота/точность.
Более того, как ни удивительно, этого не понимает и большинство разработчиков и исполнителей решений по машинному обучению.
Это вообще тема для отдельной статьи.
Многие, кто предлагает что-то «решать» с помощью нейронных сетей (большинство считает, что машинное обучение — это обязательно нейронные сети и больше ничего не знает) — просто используют стандартные фреймворки, скачивают чужие статьи и датасеты, применяют их механически, предъявляют заказчику. Ну вот же, что-то распознаёт же.
У меня выработалось для таких название: «люди 80 процентов».
Обеспечить качество в условные 80% — вообще не проблема для большинства задач. Именно таким способом — скачал пару статей, взял уже обученную нейронку, применил, показал. Ну или скачал чужой датасет, обучил нейронку — показал. С теми же 80% качества.
А больше многие и не заморачивается.
При этом, конечно, в большинстве задач ИИ порог применения не 80%, а условно говоря, 97%. И вот эти 17% требуют реальной работы и даются очень большой кровью.
Заказчик в среднем этого не понимает. Ему и 80% — чудо. Либо, наоборот, он желает 100% — за копейки.
Об этом в статье нет, а жаль.
Там даже написано:
«Очень важно до старта проекта убедиться и обговорить метрику точности решаемой задачи, особенно если от нее зависит его успешная реализация.»
Но в реальности обычно ни исполнитель, ни заказчик этой метрики не имеют.
Ну и перечисление задач обработки текстов вызывает естественное сомнение. Нет там таких успехов, что вот это перечисленное якобы типа уже решено машинным обучением.
Нейронки вообще не про обработку текста: они находят, сравнивают, классифицируют, предсказывают, модифицируют похожие формы, что хорошо работает в непрерывных пространствах.
А смысл текста крайне неустойчив относительно формы, разрывен — близкие формы могут иметь совершенно разные смыслы.
Большинство заказчиков лезут в машинное обучение действительно без метрик, и на то есть главная причина, — вера в миф, что крутые технологии принесут космические доходы. И уже нет разницы, 150 миллиардов принесёт технология или 185 миллиардов.
А реальность такова, что технологии сами по себе вообще деньги не приносят. Они могут повлиять на бизнес, но не кардинально.
Особенно показательна тут реклама. Якобы «технологии» что-то могут, на этой волне продавались RTB-решения. В итоге всё равно остались только те, у кого жирная площадка, жирный источник данных (типа подглядывать за СМС от банков) или хорошие отделы продаж по откатным схемам. Технологии там вообще самые примитивные и больше не нужны. Лучше какие-то хорошо украденные данные.
>Более того, как ни удивительно, этого не понимает и большинство разработчиков и исполнителей решений по машинному обучению.
Это вообще тема для отдельной статьи.
Вина разработчиков тут только частичная. Большинство заказчиков не настолько хорошо понимает и измеряет свой бизнес, чтобы сказать цену ошибки в бизнес единицах (рублях, часах, потраченных нервах). Поэтому исполнители и оптимизируют пункты ROC-AUC.
а какой проект именно по машинному обучению можно на сегодня считать образцово-эталлонным и с точки зрения постановки задачи и с точки зрения исполнения? я в этой области лох, с интересом бы посмотрел на образец.
Желательно вапще два — наш и забугорный, чтоб сравнить.
>>В статье совершенно выпущена одна из главных проблем: оценка качества решения. И вообще детекция наличия решения.
Все ниже — ИМХО исходя из опыта в банках, телекомах, ритейле от многих десятков миллионов клиентов до просто миллионов (больше оффлайн, чем онлайн):
1. Не стоит ждать оценки качества решения, т.к. научиться корректно ее измерять без необъяснимых «плясок» цифр из адских плюсов в адские минусы и есть самая сложная задача. Если настолько хорошо понимаете поведение своей базы, что можете с хорошей точностью померять результат своего воздействия на нее, то придумать механики игры газом/тормозом среднего чека, оттока и т. п. — уже тривиальная задача.
2. Ввиду п. 1, быстренько, в рамках относительно короткого консалтингового проекта, начать удовлетворительно мерять результаты — мало верится…
3. Ввиду п. 1, внешнему консультанту, специалисту в статистике/ML, предложить удовлетворительные методы измерения крайне сложно. Он сегодня работает с одной отраслью, а завтра — с другой. Понимания причин реакции базы на воздействия не появляется.
4. Учится корректно мерять результаты можно только на базах в десятки миллионов клиентов минимум. На маленьких базах мерять можно только примерно, но, по крайней мере, Вы понимаете почему примерно и с какой точностью.
5. У подавляющего большинства потенциальных клиентов внешних консультантов в принципе нет таких объемов бизнеса, чтобы заморачиваться с точностью измерения результата. А консультанту продавать проект с результатами плюс-минус километр сложно.
6. Когда результаты измерения начинают быть удовлетворительными выясняется, что «сотни нефти» не светят — внешнему консультанту продать такой проект на фоне текущего адового хайпа сложно.
7. Когда результат уже меряется, выясняется, что для того, чтобы денег заработать (или меньше потерять) нужны не суперпупер модели, а серьезные изменения в бизнесе. Как правило это означает и другие вложения, и амбиции акционеров/менеджмента и горизонт планирования тоже другой — не все готовы. Модели могут вполне быть и так себе…
>>Более того, как ни удивительно, этого не понимает и большинство разработчиков и исполнителей решений по машинному обучению.
Это вообще тема для отдельной статьи.
>>Вина разработчиков тут только частичная. Большинство заказчиков не настолько хорошо понимает и измеряет свой бизнес, чтобы сказать цену ошибки в бизнес единицах
ИМХО такой спор о курице и яйце: кто больше виноват — клиенты, у которых нереалистичные ожидания, но которые «меня обманывать несложно, я сам обманываться рад»; или консультанты, которые прекрасно понимают, что толку не будет, но которые ради своего личного персонального желания продолжать работать в интересной области готовы побыть «магазинами на диване»…
теперь я знаю, что если нужно решить задачу по machine learning -я будут обращаться в Корус Консалтинг. Там знают, как правильно сформулировать задачу.
УРА!
Не надо искать решения проблемы «как нам улучшить картофелекопалку» у изобретателя синхрофазотрона.
Потому что он немедленно начнет про высокое думать, вместо поиска тривиальных инженерных подходов.
Если у вас одна (3-5) моделей в продаже с твердыми данными за год (2-3) вам не нужен ML/AI/BigData (и все остальные умные слова). То есть совсем. Инсайд, эксперты, качественные методы сбора/обработки.
Если (как в примере автора) вся ваша статистика это данные о продажах 10 (100-1000) типов, с наблюдениями за 3-5 лет — регрессии, корреляции (SPSS/Access/Excel, ну или с Azure поиграйте, если захочется по модному). В общем все уже давно придумано до нас.
А «проекты с Machine Learning» оставьте для телекома/банков/ритейла, но и там все задачки (и методы решения) более-менее уже стандартизированы.
Если вы со своей «ромашкой» придете к такому специалисту (пишу без кавычек, автор безусловно Специалист), то сперва полгода будете датасет(ы) набивать (специально придуманными метриками), а затем еще полгода результаты интерпретировать. Исполнитель при этом по любому в выигрыше — ему и рейтинг в Kaggle и слайд для презентаций, но для заказчика эффективней студента с ин-та статистики взять.
(печальная история YDF и их проектов для промышленности она что, вообще уже забыта? а ведь там не самые глупые люди похожие задачки решали)
А «проекты с Machine Learning» оставьте для телекома/банков/ритейла, но и там все задачки (и методы решения) более-менее уже стандартизированы.
1. Нет, не стандартизованы, но если правильно считать нет-эффект, то, к сожалению, даже там работают только простые вещи. Просто если брать (более-менее) оффлайн-отрасли, то есть взаимосвязь: чтобы много знать про клиента Вам нужно быть большой организацией; а чем больше Вы, как организация, тем дороже Вам что-то менять. Поэтому «перелопачивать тонны руды» в поисках неочевидных и редких взаимосвязей бессмысленно — на внедрение больше потратите, чем заработате с этого узкого сегмента.
2. А еще у продавцов этой магии популярно находить статистически верные, но абсолютно бессмысленные с точки зрения бизнеса взаимосвязи. Условно, если я — банк, а мне находят, замечательную корреляцию между маркой сигарет и частотой платежей по карте. Это из разряда того, что потом всплывает на каком-нибудь Хабре в разделе «Чемпионы Биг Даты и МЛ». Как бы я рад, только какая мне, как банку, польза от таких замечательных открытий?