Вице-президент Google Поиска Панду Найак рассказал, что благодаря технологиями машинного обучения и новым типам оборудования, в "Поиске" достигли больших успехов в области понимания языка, первоначально речь шла об английском, с декабря — и о русском языке. Найак назвал созданное: "крупнейшим прорывом за последние пять лет и одним из самых грандиозных успехов за всю историю Google Поиска".
Подходы BERT (Bidirectional Encoder Representations from Transformers) позволили Google учитывать взаимодействие слов друг с другом и учитывать контекст, а не последовательности разрозненных языковых единиц.
Как правильно заказывать проекты с Machine Learning → Roem.ru
У Яндекса связь между смыслом поискового запроса и содержанием страниц учитывается с августа 2017 года (со смыслом заголовков с 2016). По интегральным оценкам сервиса "Анализатор поисковых машин" для Рунета Яндекс опережает Google по качеству поиска с ноября 2015.
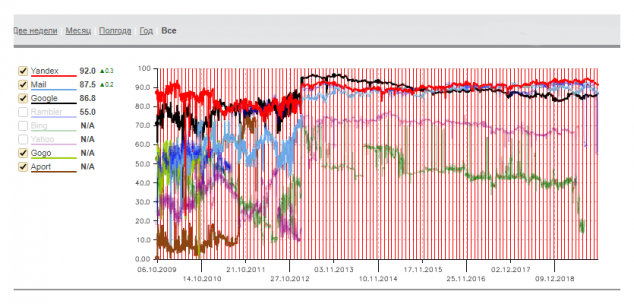
Четыре года преимущество плавно нарастало и на момент публикации, по стобалльной шкале, Yandex заслуживает оценки в 92 балла против 86.8 баллов у Google.

Добавить 9 комментариев
Бог всегда на стороне больших батальонов (с)
Т.е. на стороне больших капиталов…
Все это хорошо. И Яндекс в этом смысле будет всегда лидером (на кириллице).
Но понимать запрос и адаптировать выдачу по мере выискивания — мало.
Сложнее всего — понять, в какой именно момент, пользователь уже ищет совершенно что-то иное и перестать подтасовывать пользователю то, что пользователь искал до этого (то что больше не нужно подтасовывать…). А это иногда наоборот мешает.
Бывает ищешь ищешь, поисковик все глубюже и глубже подтасовывает выдачу. И вот тебе внезапно нужно найти что-то совершенно иное. Но поисковик уже настолько запутался в твоих запросах, что выдача по элементарному новому запросу содержит не совсем то, что ты привык ожидать от подобных запросов.
Кароче, поисковики должны научится понимать в какой именно момент «обнулить подтасовку, начать с чистого листа и выдать новую выдачу в соответствии с новыми интересами внезапного иного поискового запроса».
просто нужны и текстовые запросы и какбы усложненные параметрические, с улучшенной релевантностью. Особенно в небанальных случаях.
В какойто степени эту функцию роль подсказки выполняет, но она не совсем удобна и список выпадащий слишком мелькает, короток.
То, что «это делали и не взлетело», как нам это утвреждает И.С. — ни чего не доказывает.
Кто делал, как делал, а главное — когда делал? В 1836 году? Важно еще и возросший уровень самих массовых пользователей и ставшая высокой оснащенность гаджетами и т.п.
либо уже настало время для создания надстроек над поисковыми монстрами. Что собсно и есть в случае всех этих агрегаторах всего и вся. От букинга до скайсканера и так далее.
Их бы многие могли бы создавать и рано или поздно выклюнулись бы реальные лидеры таких сервисов, которые алгоритимизируют удачно и удобно выдачу монстров (яндекса, гугла) чтобы не приходилось рыться там.
Собсно, их бы задача и была — сделать удобный фнкционал создания запроса, самостоятельное «взаимодействие» с поисковиками и выдача квинтэссенции.
Уже все сервисы типо отелей или авиакомпаний имеют сложные, но удобные интерфейсы настройки поиска, от дат до еще кучи фильтров (при желании). Именно чтобы ничего было не надо угадывать и юзеру не предлагалась куча лишних ненужых всяких вариантов.
И только поисковики пытаются заниматься телепатией и угадывать по трем буквам, чего ищет посетитель. Причем — три буквы угадвает, да. Но дальше начинается каша, котороая съедает времени в 100500 раз больше, чем 1 раз настроить нормально запрос.
понять бы что за красивым описанием от google стоит
уточнил у эксперта что стоит за красивыми словам и — «Это небольшой апдейт, в сша затронуты 10% запросов, у нас вероятно меньше»
Гугл превращается в IBM.
IBV раз в полтора-два года объявляет о т ом, что ею в очередной раз создан ИИ, «иммунная система компьютера» и т. п. И что работают они особенно задорно на компьютерах угадайте какой марки.
Потом об этом обычно ничего не слышно.
Какой во всём этом смысл, если российский интернет уничтожается уже нескрываемыми темпами. Практически по всем запросам едва 10 пунктов (не страниц) и приписка по требованию РКН сайты заблокированы LumenDatabase org блаблабла. Блокируется абсолютно всё. Какие-то студенческие ресурсы в списке были, днище. Скоро за сайты с рецептами хрючева примутся, ибо негоже челяди помимо хрючева от НЕСТоченьзаботитсяороссиянахЛЕ есть.
У Гугла связь между смыслом поискового запроса и содержанием страниц учитывается с сентября 2013 года. Алгоритм называется Hummingbird. Но кому это интересно?